Tuesday, August 17, 2021
Great TinyML needs high-quality data
So far we have mostly written about how we enable AI applications on tiny hardware by using Binarized Neural Networks (BNNs). The use of BNNs helps us to reduce the required memory, the inference latency and energy consumption of our AI models, but there is something that we have been less vocal about that is at least as important for AI in the real world: high-quality training data.
To train tiny models, choose your data wisely
Deep learning models are famously hungry for training data, as more training data is usually the most effective way to improve accuracy. But once we started to train deep learning models that are truly tiny — with model sizes of a few hundred KB or less for computer vision tasks like person detection — we discovered that it is not so much the quantity but the quality of the training data that matters.
The key insight is that these tiny deep learning models have limited information capacity, so you cannot afford to waste precious KBs on learning irrelevant features. You have to be very strict in telling the model what you do and do not find important. We can communicate this to the model by carefully selecting its training data. Furthermore, the balance in your dataset is important because a compressed model tends to limit itself to perform well only on the concepts for which there are many samples in the training dataset. So we curate our datasets to ensure that all the important use-cases are included, and in the right balance.
Know your model
As tiny AI models become a part of our world, it is crucial that we know these models well. We have to understand in what situations they are reliable and where their pitfalls are.
High-level metrics like accuracy, precision and recall don’t provide anything close to the level of detail required here. Instead — taking inspiration from Andrej Karpathy’s Software 2.0 essay — we test our models in very specific situations. And rather than writing code we express these tests with data. Every model that we ship needs to surpass an accuracy threshold for very specific subsets of our dataset. For example, for person detection we have implemented tests for people standing far away or for people who are only showing their back, and for scenes containing coats and other fabrics that might confuse the model.
 Several samples from our
Several samples from our person_standing_back data unit test.
These data unit tests guarantee that the model will work reliably for our customers’ use-cases and also enable us to ensure our models are not making mistakes due to fairness-related attributes, such as skin color or gender. As we experiment with new training algorithms, model architectures and training datasets, our data unit tests allow us to track the progress these inventions make on the trained models that we ship to customers.
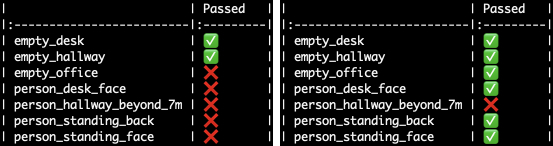 The outcome of some of our data unit tests — a standard MobileNet person detection model (left) versus Plumerai’s person detection model (right). The
The outcome of some of our data unit tests — a standard MobileNet person detection model (left) versus Plumerai’s person detection model (right). The person_hallway_beyond_7m test result shows us that this model can not yet be reliably used to detect people from large distances.
Public datasets: handle with care
Public datasets are usually composed of photos taken by people for the enjoyment of people, such as photos of concerts, food or art. These photos are typically very different from the scenes in which TinyML/low-power AI products are deployed. For example, the dark photos in public datasets are mostly from concerts and almost always have people in them. So if this dataset is used to train a tiny deep learning model, the model will try to take a shortcut and associate dark images with the presence of people. This hack works fine as long as the model is evaluated on the same distribution of images, as is the case in the validation sets of public datasets, but will cause problems once the model is deployed in a smart doorbell camera. In addition, public datasets often contain misclassified images, images encoding harmful correlations and images that although technically labelled correctly are too difficult to classify correctly.
 Most dark photos in the public Open Images dataset are from concerts and contain people. A tiny deep learning model trained on this dataset will try to take a problematic shortcut and associate dark images with the presence of people.
Most dark photos in the public Open Images dataset are from concerts and contain people. A tiny deep learning model trained on this dataset will try to take a problematic shortcut and associate dark images with the presence of people.
To circumvent the many problems of public datasets, we at Plumerai collect our own data — straight from the cameras used in TinyML products in the situations that our products are intended for. But that does not mean that we do not use any public datasets to train our models. We want to benefit from the scale and diversity of these datasets, while mitigating their quality issues. So we use our own data and analysis methods to automatically identify specific issues stemming from sampling biases in the public datasets and solve those problematic correlations that our models are sensitive to.
 The images in public person detection datasets (left) are largely irrelevant to the scenes encountered by TinyML devices in the real-world (right).
The images in public person detection datasets (left) are largely irrelevant to the scenes encountered by TinyML devices in the real-world (right).
 One of the tools we can use to debug our tiny AI models are saliency maps. They allow us to see what our models are correctly (left) or incorrectly (right) triggered by.
One of the tools we can use to debug our tiny AI models are saliency maps. They allow us to see what our models are correctly (left) or incorrectly (right) triggered by.
Building the tiny AI model factory
Although new training optimizers and new model architectures get most of the attention, there are many other components required to build great AI applications on tiny hardware. Data unit tests and tools for dataset curation are some of the components that are mentioned above, but there are many more. We build tools to identify what data needs to be labelled, use large models in the cloud for auto labeling our datasets and combine these with human labelling. We build the whole infrastructure that is necessary to go as fast as possible through our model development cycle: train a tiny AI model, test it, identify the failure cases, collect and label data for those failure cases and then go through this cycle again and again. All these components together allow us to build tiny but highly accurate AI models for the real world.
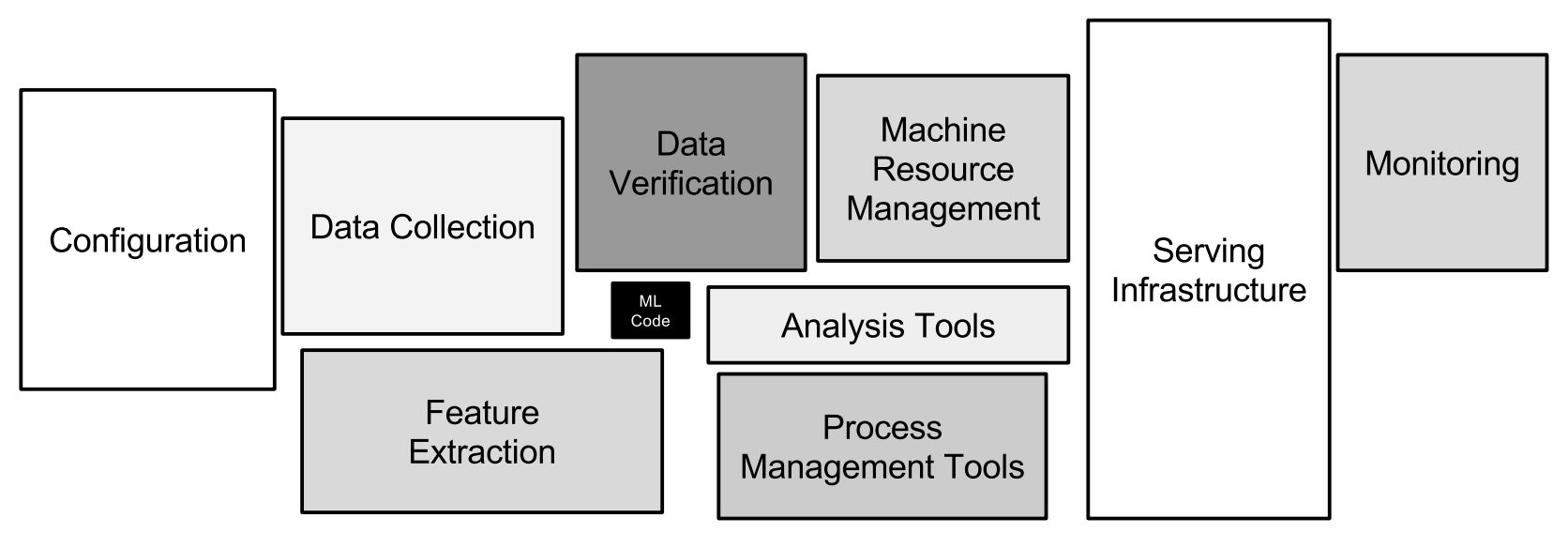 ML code is just one small component of the large and complex tiny AI model factory that we are building. From Sculley et al. (2015).
ML code is just one small component of the large and complex tiny AI model factory that we are building. From Sculley et al. (2015).